Plot Gower's disimilarity values for each study (Transitivity evaluation)
Source:R/plot.study.dissimilarities_function.R
plot_study_dissimilarities.RdIllustrating the range of Gower's dissimilarity values for each study in the network, as well as their between- and within-comparison dissimilarities
Usage
plot_study_dissimilarities(
results,
axis_title_size = 12,
axis_text_size = 12,
strip_text_size = 11,
label_size = 3.5
)Arguments
- results
An object of S3 class
comp_clustering. See 'Value' incomp_clustering.- axis_title_size
A positive integer for the font size of axis title (both axes).
axis_title_sizedetermines the axis.title argument found in the theme's properties in the R-package ggplot2.- axis_text_size
A positive integer for the font size of axis text (both axes).
axis_text_sizedetermines the axis.text argument found in the theme's properties in the R-package ggplot2.- strip_text_size
A positive integer for the font size of facet labels.
strip_text_sizedetermines the strip.text argument found in the theme's properties in the R-package ggplot2.- label_size
A positive integer for the font size of labels appearing on each study-specific segment.
label_sizedetermines the size argument found in the geom's aesthetic properties in the R-package ggplot2.
Value
A horizontal bar plot illustrating the range of Gower's dissimilarity
values for each study with those found in other comparisons. The
study names appear on the y-axis in the order they appear in results
and the dissimilarity values appear on the x-axis. Red and blue points refer
to the (average) within-comparison and between-comparison dissimilarity,
respectively, for each study.
A data-frame on the (average) within-comparison and between-comparison
dissimilarities for each study alongside the study name and comparison.
The last two columns refer to the within-comparison and between-comparison
dissimilarities, respectively, after replacing with the maximum value in the
multi-arm trials. These two columns should be used as a covariate in the
function study_perc_contrib to obtain the
percentage contribution of each study based on the covariate values.
Details
The range of Gower's dissimilarity values for each study versus the remaining studies in the network for a set of clinical and methodological characteristics that may act as effect modifiers. Gower's dissimilarities take values from 0 to 1, with 0 and 1 implying perfect similarity and perfect dissimilarity, respectively.
The unique dissimilarity values appear as dotted, vertical, grey lines on each study
References
Gower J. General Coefficient of Similarity and Some of Its Properties. Biometrics 1971;27(4):857–71. doi: 10.2307/2528823
Examples
# \donttest{
# Fictional dataset
data_set <- data.frame(Trial_name = paste("study", as.character(1:7)),
arm1 = c("1", "1", "1", "1", "1", "2", "2"),
arm2 = c("2", "2", "2", "3", "3", "3", "3"),
sample = c(140, 145, 150, 40, 45, 75, 80),
age = c(18, 18, 18, 48, 48, 35, 35),
blinding = as.integer(c("yes", "yes", "yes", "no", "no", "no", "no")))
#> Warning: NAs introduced by coercion
# Obtain comparison dissimilarities (informative = TRUE)
res <- comp_clustering(input = data_set,
drug_names = c("A", "B", "C"),
threshold = 0.13, # General research setting
informative = TRUE,
get_plots = TRUE)
#> - 3 observed comparisons (0 single-study comparisons)
#> - Dropped characteristics: blinding
#> Warning: data length [63] is not a sub-multiple or multiple of the number of columns [2]
#> $Trials_diss_table
#> study 1 B-A study 2 B-A study 3 B-A study 4 C-A study 5 C-A
#> study 1 B-A 0.000 NA NA NA NA
#> study 2 B-A 0.023 0.000 NA NA NA
#> study 3 B-A 0.045 0.023 0.000 NA NA
#> study 4 C-A 0.955 0.977 1.000 0.000 NA
#> study 5 C-A 0.932 0.955 0.977 0.023 0.000
#> study 6 C-B 0.579 0.602 0.624 0.376 0.353
#> study 7 C-B 0.556 0.579 0.602 0.398 0.376
#> study 6 C-B study 7 C-B
#> study 1 B-A NA NA
#> study 2 B-A NA NA
#> study 3 B-A NA NA
#> study 4 C-A NA NA
#> study 5 C-A NA NA
#> study 6 C-B 0.000 NA
#> study 7 C-B 0.023 0
#>
#> $Comparisons_diss_table
#> B-A C-A C-B
#> B-A 0.03 NA NA
#> C-A 0.97 0.02 NA
#> C-B 0.59 0.38 0.02
#>
#> $Total_dissimilarity
#> comparison total_dissimilarity index_type
#> 5 C-A vs C-B 0.38 Between-comparison
#> 3 B-A vs C-B 0.59 Between-comparison
#> 2 B-A vs C-A 0.97 Between-comparison
#> 4 C-A 0.02 Within-comparison
#> 6 C-B 0.02 Within-comparison
#> 1 B-A 0.03 Within-comparison
#>
#> $Types_used
#> characteristic type
#> 1 sample double
#> 2 age double
#> 3 blinding integer
#>
#> $Total_missing
#> [1] "33.33%"
#>
#> $Within_comparison_dissimilarity
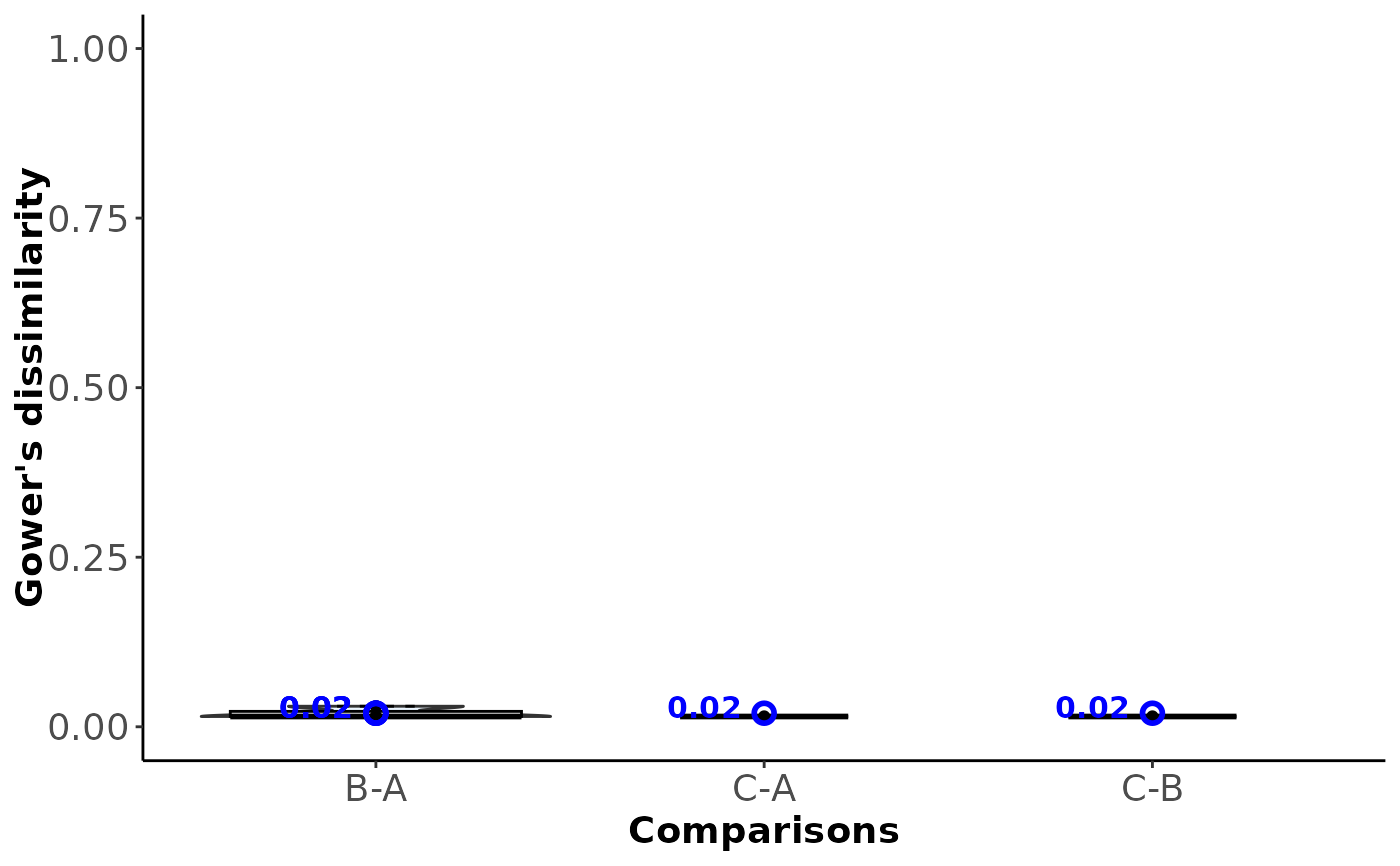 #>
#> $Between_comparison_dissimilarity
#>
#> $Between_comparison_dissimilarity
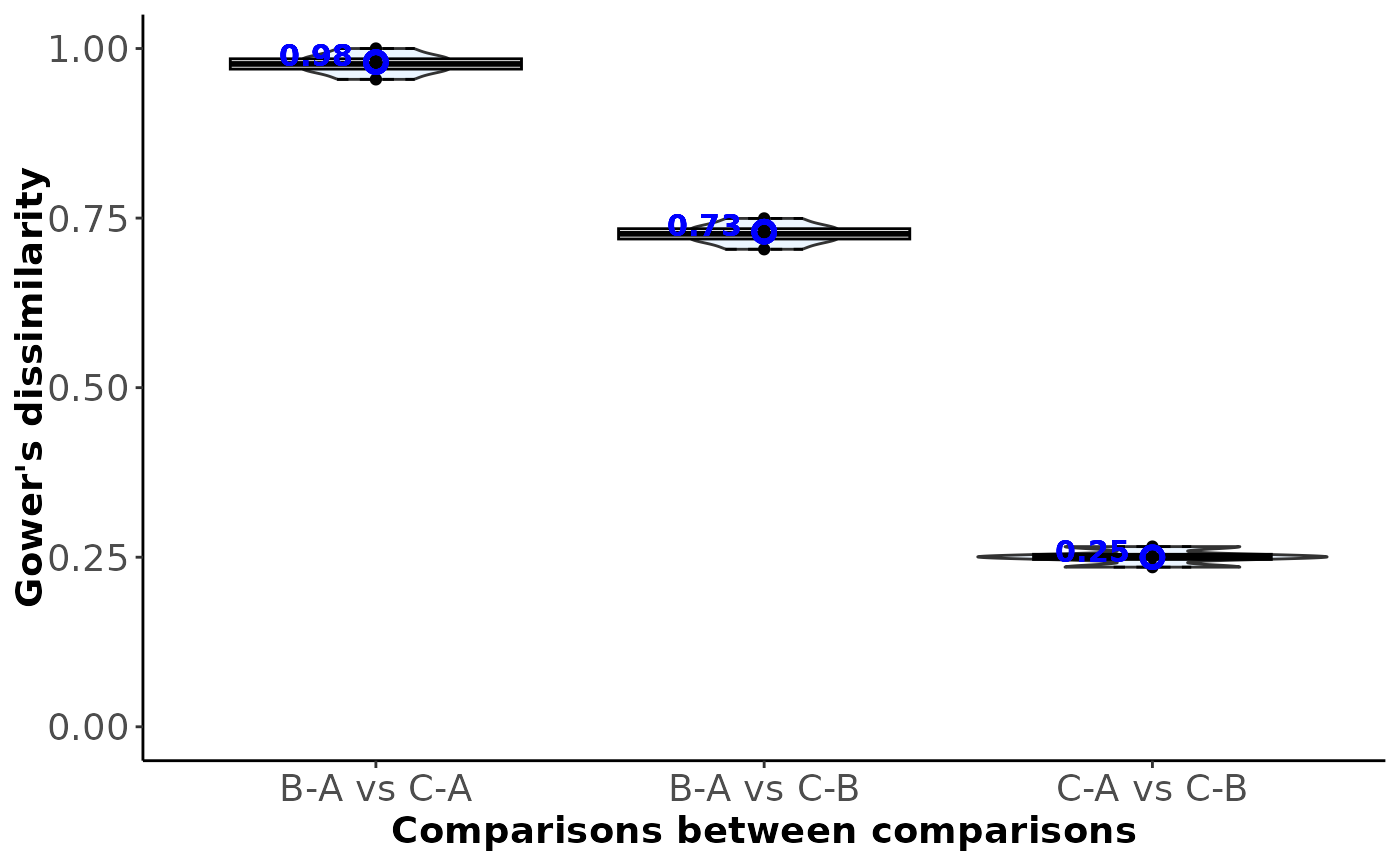 #>
#> $Dissimilarity_heatmap
#>
#> $Dissimilarity_heatmap
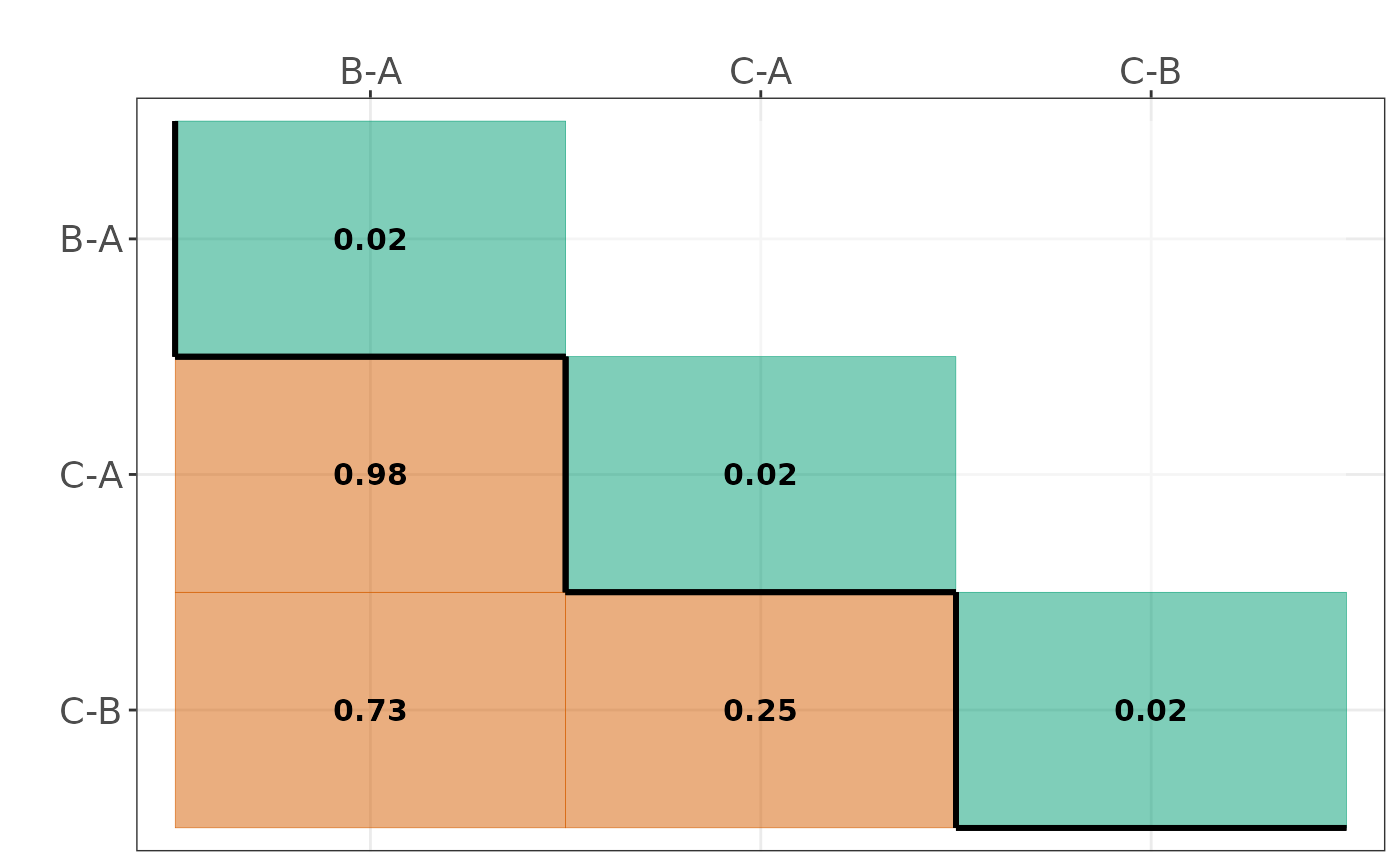 #>
#> attr(,"class")
#> [1] "comp_clustering"
plot_study_dissimilarities(results = res,
axis_title_size = 12,
axis_text_size = 12,
strip_text_size = 11,
label_size = 3.5)
#> [[1]]
#>
#> attr(,"class")
#> [1] "comp_clustering"
plot_study_dissimilarities(results = res,
axis_title_size = 12,
axis_text_size = 12,
strip_text_size = 11,
label_size = 3.5)
#> [[1]]
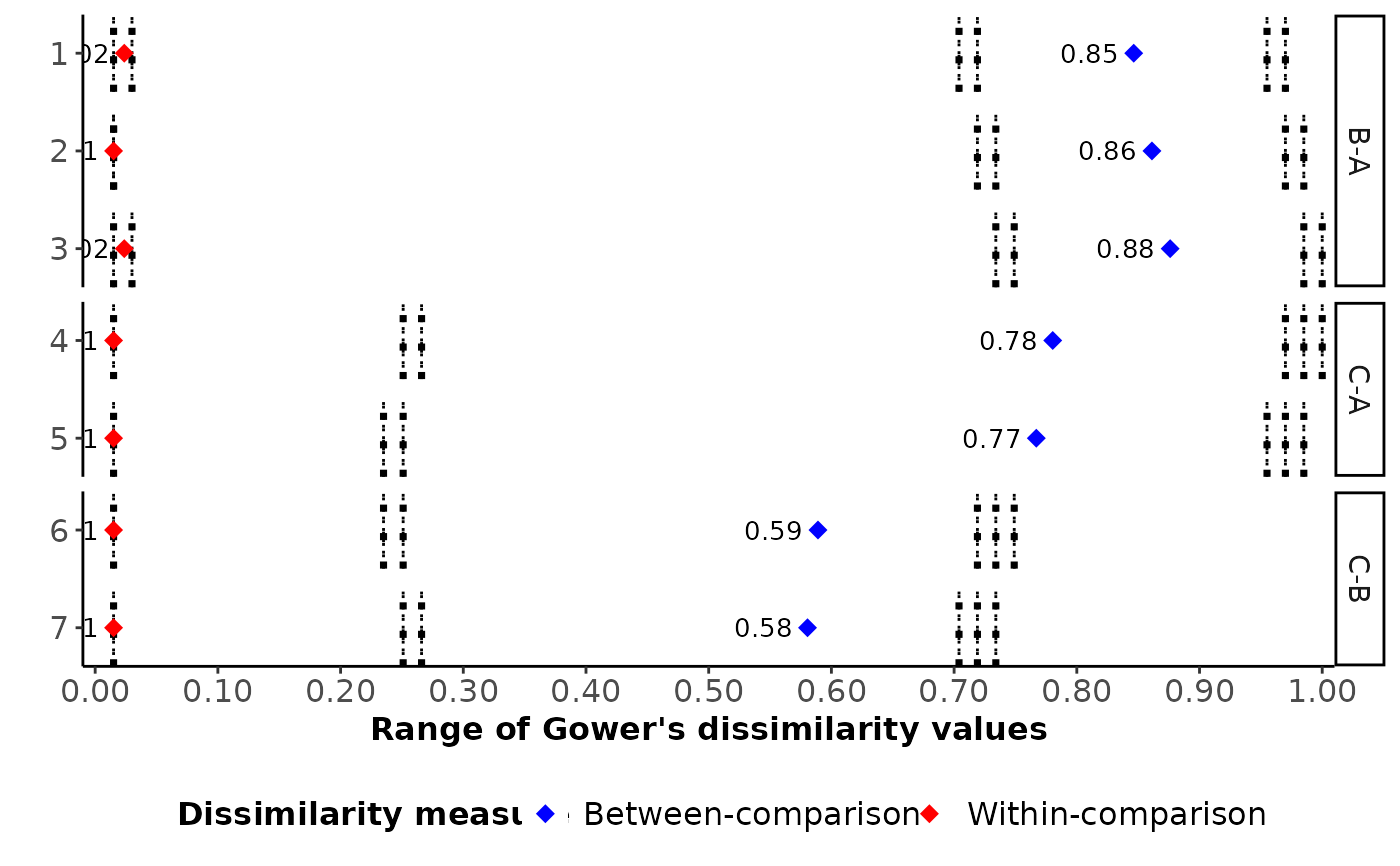 #>
#> $diss_values
#> study_id study comp within_value between_value within_multiarm
#> 1 1 study 1 B-A 0.03573514 0.7786247 0.03573514
#> 2 2 study 2 B-A 0.02300000 0.8006558 0.02300000
#> 3 3 study 3 B-A 0.03573514 0.8225432 0.03573514
#> 4 4 study 4 C-A 0.02300000 0.7957806 0.02300000
#> 5 5 study 5 C-A 0.02300000 0.7747468 0.02300000
#> 6 6 study 6 C-B 0.02300000 0.5201934 0.02300000
#> 7 7 study 7 C-B 0.02300000 0.5111870 0.02300000
#> between_multiarm
#> 1 0.7786247
#> 2 0.8006558
#> 3 0.8225432
#> 4 0.7957806
#> 5 0.7747468
#> 6 0.5201934
#> 7 0.5111870
#>
# }
#>
#> $diss_values
#> study_id study comp within_value between_value within_multiarm
#> 1 1 study 1 B-A 0.03573514 0.7786247 0.03573514
#> 2 2 study 2 B-A 0.02300000 0.8006558 0.02300000
#> 3 3 study 3 B-A 0.03573514 0.8225432 0.03573514
#> 4 4 study 4 C-A 0.02300000 0.7957806 0.02300000
#> 5 5 study 5 C-A 0.02300000 0.7747468 0.02300000
#> 6 6 study 6 C-B 0.02300000 0.5201934 0.02300000
#> 7 7 study 7 C-B 0.02300000 0.5111870 0.02300000
#> between_multiarm
#> 1 0.7786247
#> 2 0.8006558
#> 3 0.8225432
#> 4 0.7957806
#> 5 0.7747468
#> 6 0.5201934
#> 7 0.5111870
#>
# }